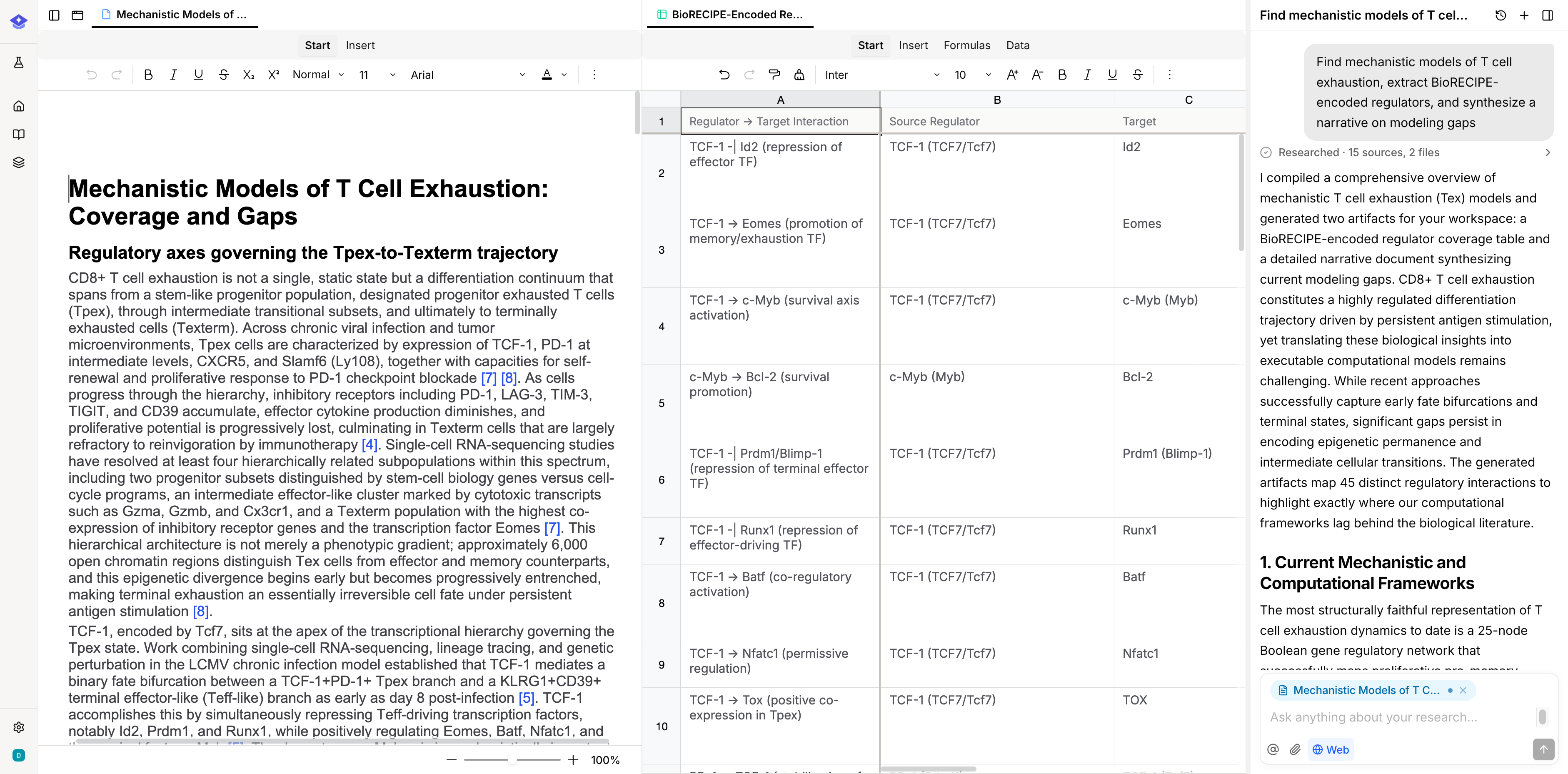
Every finding, structured and citable.
When the assistant reads a paper, every finding is captured with a verbatim quote and a canonical entity identifier. The same records power your tables, your knowledge graphs, and your drafts. Read once. Query forever.
Every citation is one click from the line that wrote it.
When the assistant synthesizes across papers, each finding carries a numbered chip. Click the chip, the source PDF opens at the exact line, highlighted. Drafts and tables stay anchored to verifiable text, not paraphrase.
Retrieval-Augmented Generation: State of the Field
RAG as a paradigm for grounded generation
Retrieval-Augmented Generation has emerged as a foundational paradigm for grounding large language model outputs in verifiable external knowledge, integrating parametric memory with non-parametric memory sourced from external knowledge repositories queried at inference time.3 In practice, RAG systems augment prompts with passages retrieved from vector databases of document embeddings.5
A comprehensive characterization identifies three broad paradigms: Naive RAG, Advanced RAG, and Modular RAG. All three share the foundational triad of retrieval, augmentation, and generation, but differ in how those components are orchestrated.2
Convergent findings across retrieval and generation
REALM demonstrated a key architectural milestone by training its retrieval and generative modules together, enabling tighter alignment between what is fetched and what is ultimately generated.1The performance envelope is not uniform across tasks: for question answering, the retrieval-recall threshold required to surpass a base LLM ranges from 0.2 to 1.0, with accuracy improvements reaching up to 0.6.3
The robustness frontier
Imperfect retrieval can introduce irrelevant or misleading information that undermines downstream generation. Adaptive methods such as ASTUTE RAG incur a marginal cost increase while delivering substantial accuracy gains across long-form QA benchmarks.4
A Comprehensive Survey of Retrieval-Augmented Generation (RAG): Evolution, Current Landscape and Future Directions
Retrieval-Augmented Generation for Large Language Models: A Survey
Gao, Xiong, Gao, Jia, Pan, Bi, Dai, Sun, Wang, Wang
Understanding the Design Decisions of Retrieval-Augmented Generation Systems
Astute RAG: Overcoming Imperfect Retrieval Augmentation and Knowledge Conflicts for Large Language Models
Deploying Large Language Models With Retrieval Augmented Generation
Prabhune, Berndt · 2024
Click any citation chip and the source PDF opens at the exact line, highlighted.
From cited finding to the exact line in the source PDF.
Each structured finding carries its verbatim quote. Click the citation chip, the PDF opens to the highlighted passage. No paraphrase layer between you and the source.
“...where high PD-L1 expression in tumor cells correlated with longer survival in checkpoint inhibitor responders.”
Every finding is one click from the original line. They stay in your project, ready for the next question.
Findings as data, not summaries.
Each finding is captured with its subject, its relationship, its object, and a verbatim quote. Queryable, not free prose.
Click any finding, the PDF viewer scrolls to the exact line, highlighted. No paraphrase layer.
Entities ground to canonical identifiers where applicable. The same entity across papers collapses automatically.
Every finding lives in your evidence database. Reading one paper compounds into every project after it.
Compounding evidence, not single-shot answers.
Most AI research tools synthesize on every query and throw away the structured work. EvidX captures it once. The next time you ask 'compare these five drugs', the table builds from your existing findings, instantly.
- Same findings power tables, plots, graphs, and drafts
- Conflicts between papers surface at capture time, not query time
- Hundreds of papers aggregate in one click, without re-reading